More than 80% of enterprise data exists in unstructured form — PDFs, emails, reports, regulatory filings. These sources routinely contain business-critical information, yet extracting meaningful insight from them at scale remains a persistent challenge. BigQuery Graph and Kineviz GraphXR address this directly by combining into a single, streamlined workflow: BigQuery handles graph construction and storage, while GraphXR gives analysts an interactive, visual environment to explore relationships, verify findings, and trace every insight back to its source.
Retrieval-augmented generation (RAG) and vector search have become the dominant approaches for working with unstructured data — but they have limits. For trend analysis, cross-entity comparison, multi-hop reasoning, and explainable decision support, graph structures offer meaningful advantages by capturing context and relationship mapping that RAG alone cannot. The approach described here is built around an "evidence-first" philosophy: every element in the knowledge graph preserves the nuance of its original source and remains fully traceable, making the resulting analysis both verifiable and trustworthy. This post walks through a concrete example — applying BigQuery AI Functions, BigQuery Graph, and Kineviz GraphXR to Fortune 500 SEC filings — without requiring complex ETL pipelines, data duplication, or standalone graph databases.
From fragmented pipelines to a unified platform
Traditional unstructured analytics pipelines tend to be sprawling by design. A typical setup involves object storage for raw files, a custom parsing service, a separate AI extraction layer, a standalone graph database, and a BI tool layered on top. The result is a fragile architecture: difficult to maintain, prone to data synchronization issues, and riddled with potential failure points.
BigQuery consolidates this significantly. Raw documents live in Google Cloud Storage, while text extraction, Gemini-powered inference, and graph creation all execute within the same platform. There is no data movement between systems, no complex service orchestration, and no risk of out-of-sync data copies accumulating over time. The pipeline stays simple, maintainable, and fully auditable — without requiring bespoke infrastructure.
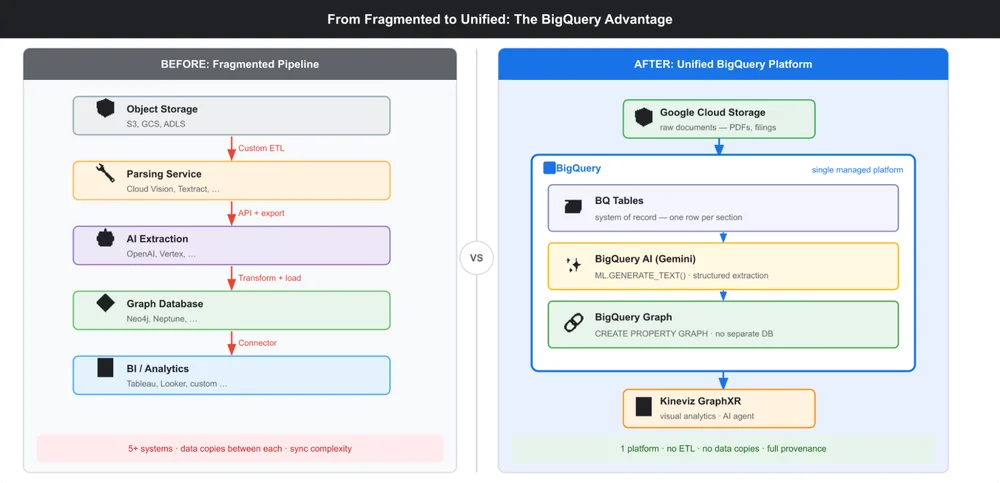
BigQuery pipeline: From unstructured to structured
The pipeline was applied to SEC 10-K filings from Fortune 500 companies spanning 2020 to 2024. Each filing runs approximately 100 pages of dense, descriptive text. The schema was designed so that each Company connects to Competitors (COMPETES_WITH), Risks (FACES_RISK), and Markets (ENTERING / EXITING / EXPANDING), following a four-step process.
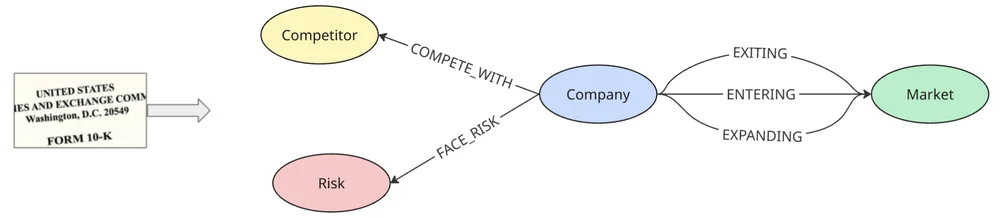
1. Ingest and parse. 10-K filings are retrieved from SEC EDGAR, converted from Standard Generalized Markup Language (SGML) to Markdown while preserving hierarchical structure, and loaded into BigQuery via Cloud Storage.
2. Focus on key signal sections. Rather than processing entire 100-page filings, extraction targets only the sections most relevant to market moves, risks, and competitive positioning — specifically the Business, Risk Factors, and MD&A sections. Every row in BigQuery retains essential metadata: year, company name, CIK, section ID, and a direct URL back to the original source filing.
3. Gemini for extraction. Using AI.GENERATE_TEXT() with Gemini 3 Pro, each section is processed to return structured JSON detailing competitors, risks, market actions, and opportunities — with every element grounded by evidence text drawn directly from the filing. The entire process runs within BigQuery, with no external orchestration or data movement required.
4. Declaring the graph. The structured JSON is decomposed into separate node and edge tables, then mapped into a fully traversable graph using a single Data Definition Language (DDL) statement — enabling graph queries without joins.
- code_block
- <ListValue: [StructValue([('code', 'CREATE PROPERTY GRAPH sec_filings.SecGraph\r\n NODE TABLES (\r\n nodes_company, nodes_competitor, nodes_risk, nodes_market, nodes_opportunity\r\n )\r\n EDGE TABLES (\r\n edges_competes SOURCE nodes_company DESTINATION nodes_competitor LABEL COMPETES_WITH,\r\n edges_faces_risk SOURCE nodes_company DESTINATION nodes_risk LABEL FACES_RISK,\r\n edges_entering SOURCE nodes_company DESTINATION nodes_market LABEL ENTERING\r\n -- plus EXITING, EXPANDING, PURSUING\r\n );'), ('language', ''), ('caption', <wagtail.rich_text.RichText object at 0x7fe849bdd6d0>)])]>
The pipeline extracted 87,000 entities and more than 20,000 competitor mentions. After entity resolution and normalization, those mentions consolidated into approximately 8,100 distinct competitors — transforming raw SEC filings into a structured knowledge graph of the competitive landscape.
Unlocking hidden insights with Kineviz GraphXR
GraphXR connects directly to BigQuery Graph, giving analysts an interactive environment to explore and interrogate the data through low-code workflows — no query writing required. This means strategy, compliance, and research teams can work directly with the graph and refine their analyses independently.
GraphXR's AI-assisted workflows let users define analytical tasks in plain language — for example, "show me Apple's competitive trajectory over time" — generating dashboards that remain linked to a live graph view. As the graph view changes, dashboard charts update dynamically. One finding that emerges clearly from this approach: the number of Fortune 500 companies citing Apple as a direct competitor has remained relatively stable at around 14 over the period studied — a pattern that would be invisible when reading individual filings in isolation.
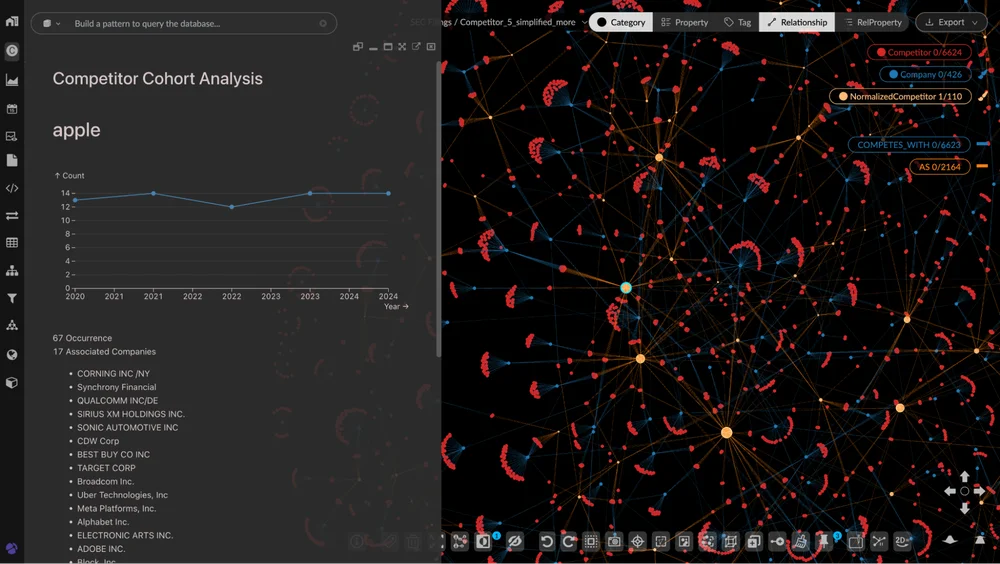
Dashboard: Companies Citing Apple Over Time
The AI-powered Visual Analysis Agent adds another layer of analytical depth. After using GraphXR's "trace neighbor" function to surface companies that cite Google as a competitor, the Agent surfaces complex cross-industry relationships that aren't obvious from the filing text alone. A notable example: AES Corp., an energy utility, appears in contexts that suggest a coopetition dynamic — reflecting the broader industry shift toward cloud and AI infrastructure adoption.
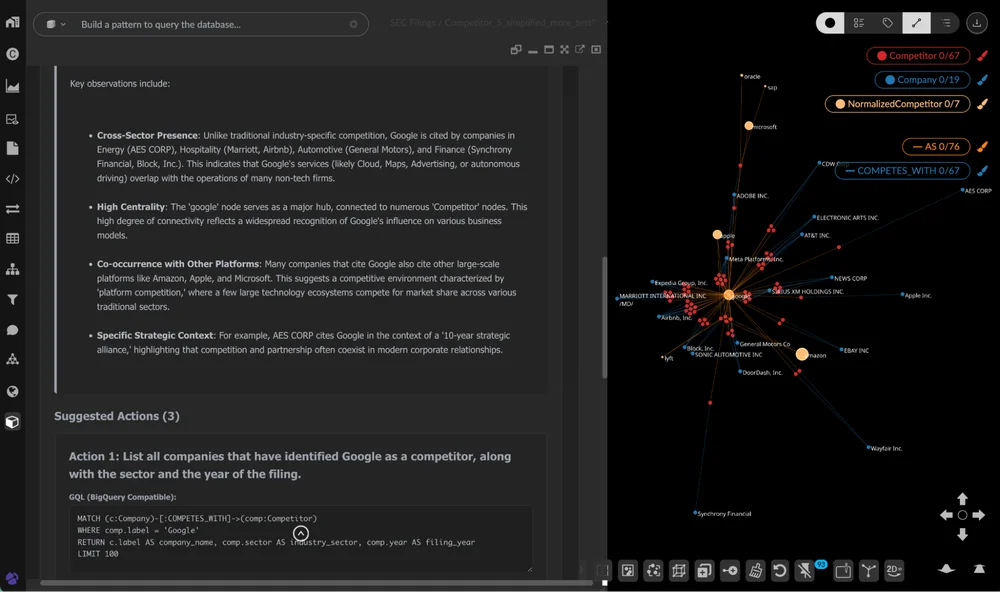
Competitive analysis with agent reasons over both graph structure and node properties
Auditability is built into the workflow from the start. Every node in the graph links directly to its location within the original SEC filing. Analysts can trace any insight back to its source and validate findings in context. Selecting a risk entity, for instance, surfaces a URL that takes the reader to the precise passage in the document where that risk was identified.
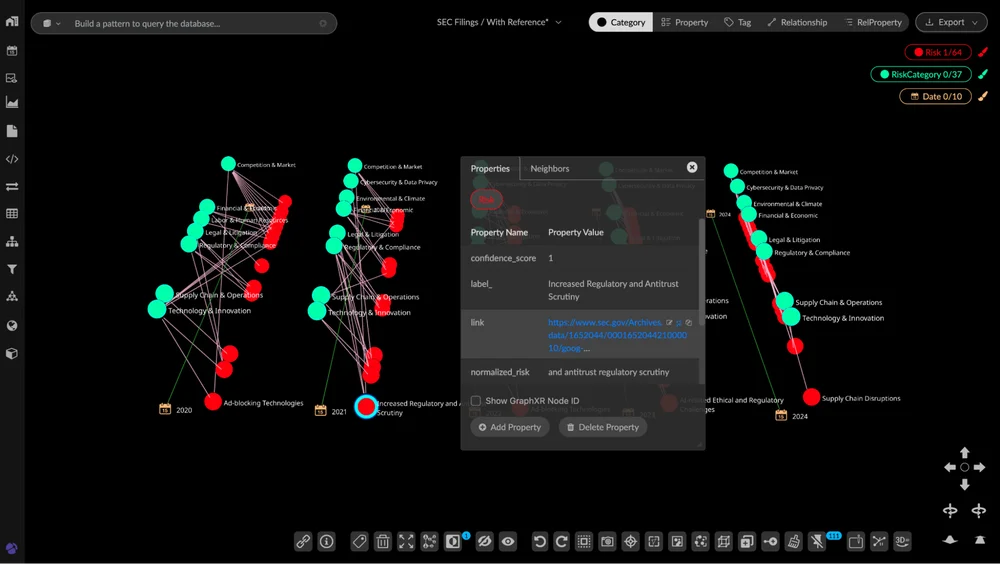
Risk analysis with a direct, clickable link to the precise location of the extracted information in the source document.
Why this matters
Together, BigQuery Graph and Kineviz GraphXR deliver four core advantages for enterprise data teams:
- Simplicity: Fewer systems, fewer copies — data stored in BigQuery is explored and analyzed directly in GraphXR within a fully managed, integrated platform, with no data movement or duplication required.
- Scalability: BigQuery handles millions of documents and billions of extracted facts without the overhead of custom graph infrastructure.
- Explainability: Every insight traces back to its source evidence, with validation available in a single click.
- Flexibility: New questions or entity types don't require rebuilding the extraction model — extending the schema is enough.
Most enterprise knowledge remains locked inside unstructured data. BigQuery AI Functions, BigQuery Graph, and Kineviz GraphXR together form an end-to-end pipeline that brings graph-based reasoning, evidence-first analytics, and interactive exploration into a single streamlined workflow — making that trapped intelligence accessible and actionable.
Get started
Learn more about BigQuery Graph in the official documentation or jump straight into creating your first graph. Kineviz GraphXR is available on the Google Cloud Marketplace. To see the technology in action, explore the Fortune 500 tutorial in the GitHub notebook or watch the accompanying video.
Related reading:


